L’Intelligenza Artificiale sta imparando a scrivere libri di testo

L’Intelligenza Artificiale sta imparando a scrivere libri. Non romanzi o thriller, ma quelli che sono comunemente definiti Wikibook. Sono libri di testo su argomenti verticali, “composti” dalla raccolta di articoli dell’enciclopedia online Wikipedia. Se c’è solo da copiare e incollare contenuti già online, che difficoltà ci sarà? Al contrario di quello che si possa pensare, è difficilissimo. Il problema è che Wikipedia è incredibilmente vasta, e decidere che cosa includere in un libro di testo e che cosa scartare è un compito insidioso. Il rischio da evitare è ritrovarsi con un “mattone” di 550 capitoli, che sarebbe tanto indigesto quanto inutile.
Ciò solleva una domanda interessante: è possibile che i progressi dell’Intelligenza Artificiale consentano di modificare automaticamente i contenuti di Wikipedia in modo da creare un libro di testo coerente e utile? A porsi la domanda sono stati Shahar Admati e i suoi colleghi presso l’Università Ben-Gurion del Negev in Israele. La loro risposta è un algoritmo capace di generare automaticamente Wikibook utilizzando l’apprendimento automatico dell’Intelligenza Artificiale. Stando a quanto spiegano, il loro produttore di Wikibook può generare un intero Wikibook, senza coinvolgimento umano.

L’approccio che hanno usato i ricercatori è relativamente semplice. Hanno passato in rassegna 6.700 Wikibook esistenti e li hanno valutati per qualità, correttezza dei contenuti e lunghezza. Ne hanno selezionati 407 da usare per “addestrare” l’Intelligenza Artificiale. A questo punto hanno diviso in più parti i compiti da svolgere per creare un Wikibook, a seconda delle diverse abilità di apprendimento automatico che erano necessarie. L’attività è partita dal titolo, generato da un essere umano, e dalla descrizione sommaria di un concetto (per esempio, Machine Learning – The Complete Guide). Un algoritmo ha scansionato gli articoli di Wikipedia e link in essi contenuti per determinare quali erano abbastanza rilevanti da essere inclusi nel libro, tra milioni di contenuti disponibili.
Prendendo esempio dai 407 libri che avevano “studiato”, i computer hanno identificato gli articoli da includere, affinando poi la selezione con un’analisi che permetteva di ricavare un libro con una struttura quanto più simile a quella dei libri generati dall’uomo. Quindi è stata operata la divisione in capitoli: un compito di clustering, ossia di selezione e raggruppamento di elementi omogenei in un insieme di dati. Ultimo passo è stato quello di determinare l’ordine in cui i contenuti sarebbero apparsi in ciascun capitolo. I ricercatori sono stati in grado di produrre versioni automatizzate di Wikibook che erano già stati creati dagli esseri umani. Contenevano buona parte degli stessi materiali, spesso in un ordine simile.
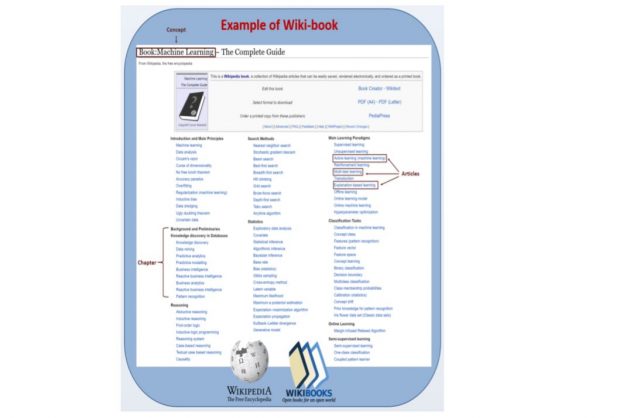

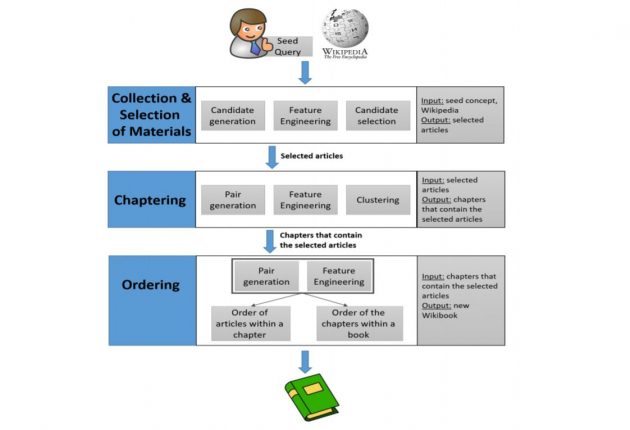

Admati e colleghi intendono ora produrre una serie di Wikibook su argomenti non ancora inclusi nei libri generati dall’uomo, e valutarne i risultati. Come? Monitorando le visualizzazioni online e le modifiche che vengono apportate dai lettori. Ricordiamo infatti che i Wikibook, come gli articoli di Wikipedia, sono contenuti aperti, passibili di modifiche su segnalazioni di inesattezze da parte della comunità.
Il lavoro è ancora in fase di ricerca, ma il potenziale è altissimo, perché potrebbe portare alla produzione di libri di testo su una vasta gamma di argomenti. La speranza è che l’Intelligenza Artificiale sia in grado di individuare le anche le inesattezze che ci sono in Rete, e di produrre libri dai contenuti corretti e affidabili.