

Nel post precedente ho evidenziato alcuni possibili dubbi sulle risposte di un sistema ad apprendimento automatico. Dubbi legittimi: trovo del tutto giustificata l’esitazione di un medico ad accettare ad occhi chiusi una diagnosi automatica; tanto più che, come abbiamo visto, la macchina può sbagliare clamorosamente. Nel mondo c’è un’intensa ricerca per far diventare più trasparente la “scatola nera” costituita dalle macchine ad apprendimento, in particolare dalle celebratissime reti neurali. Vediamo tre di questi approcci alla cosiddetta Intelligenza Artificiale spiegabile.
Ci piacerebbe capire cosa ha causato la risposta di una macchina, per esempio, ad un problema di classificazione. Un metodo interessante, quando l’input sia un’immagine, è quello delle mappe di rilevanza (heat maps): con un’opportuna programmazione (S. Lapuschkin et al.: Unmasking Clever Hans predictors and assessing what machines really learn, Nature Communications, 2019) il sistema può segnalare i pixel che hanno determinato la risposta.
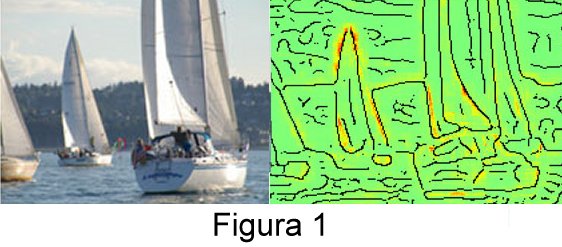
Per esempio, nella Figura 1 vediamo una foto che la rete neurale degli Autori ha correttamente classificato come “barche a vela”. Di fianco c’è una pre-elaborazione: i contorni degli oggetti; su questi il sistema ha segnato in rosso i pixel su cui ha basato la classificazione. Questo metodo permette di smascherare un effetto “Hans l’intelligente”, cioè una risposta giusta dovuta al motivo sbagliato.
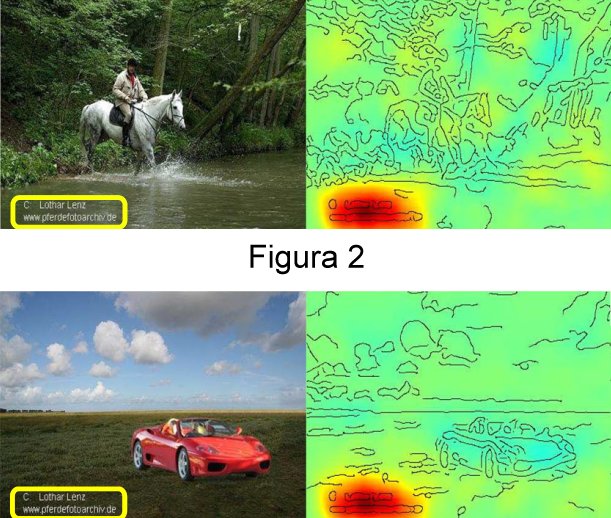
Guardate la Figura 2 in alto: il sistema riconosce che in questa foto c’è un cavallo. Però la mappa di rilevanza mostra che il particolare decisivo non è l’animale, bensì l’etichetta in basso; in effetti un quinto delle immagini di cavalli, con cui era stata addestrata la macchina, aveva la stessa etichetta. Nella figura in basso gli Autori hanno messo una Ferrari e la solita etichetta: il sistema ci casca e risponde “cavallo”! La mappa di rilevanza ci segnala dov’è l’inghippo.
Un’altra via è l’approfondimento matematico. La medaglia Fields Cédric Villani ha dato la prima scossa con un accurato rapporto richiesto dal governo francese; l’Unione Matematica Italiana ha costituito un gruppo di ricerca sull’apprendimento automatico. In generale, la comunità matematica mondiale si sta finalmente rendendo conto dell’importanza (e del fascino) dei problemi provenienti dalle nuove tecnologie, come testimoniato dal premio Abel appena conferito a L. Lovász e ad A. Widgerson. La speranza, per le macchine ad apprendimento, è che nuovi modelli matematici possano migliorare e rendere più comprensibili le loro classificazioni, traduzioni, interpretazioni, decisioni. Guardate, per esempio, le conclusioni di questo articolo al confine tra matematica e filosofia.
Un modello immediato è questo: possiamo pensare alla rete neurale come una pallina appoggiata su un pendio. L’addestramento agisce sulla pallina come la gravità, portandola passo dopo passo verso un fondo valle, dove si stabilizza. Domanda cruciale: questo è il fondo della vallata più bassa che ci sia (e di conseguenza la rete ha il funzionamento migliore possibile) o è il fondo di una valletta ad alta quota? Lo studio matematico di questo paesaggio collinare (multidimensionale) può risultare essenziale.
Il gruppo di Andreas Holzinger propugna una via drasticamente diversa: l’umano-nel-ciclo. Finora l’operatore umano è in fondo al ciclo, cioè prende quello che la macchina gli dà; punto. Anche lì l’umano può avere un ruolo passivo o attivo. Pensate al monitoraggio automatico delle stazioni della metropolitana: il sistema è programmato per riconoscere situazioni di rischio, cioè risse, incidenti eccetera. Come lo vogliamo utilizzare? Preferiamo che il sistema agisca autonomamente (bloccando i treni, chiudendo la stazione o peggio) o che avverta un operatore umano che prende le decisioni? Il compromesso è fra la perdita di tempo prezioso e il rischio di falsi allarmi.
Holzinger, interessato soprattutto al contesto delle diagnosi mediche, va oltre: l’operatore umano può essere parte del processo di decisone della macchina, magari aiutato da un’efficace visualizzazione di quello che succede al suo interno. I motori di ricerca a “risposta in rilevanza” (relevance feedback) ne sono un esempio rudimentale; anche Google ne ha sperimentato uno: SearchWiki.
Vi illustro come sarà Google se e quando funzionerà a risposta in rilevanza. Immaginate di mettere la parola “penna”; vi vengono fuori diverse foto di penne per scrivere, ed è proprio quello che volevate; ma in mezzo viene anche una penna di gabbiano. Capita, no? Di solito non ci facciamo caso e basta; invece qui potrete escluderla o almeno spostarla in fondo alla lista. Il sistema si riconfigurerà e le nuove risposte saranno più aderenti alle vostre intenzioni. Anche qua la matematica può ricoprire un ruolo importante, per esempio giocando sul concetto astratto di distanza.



